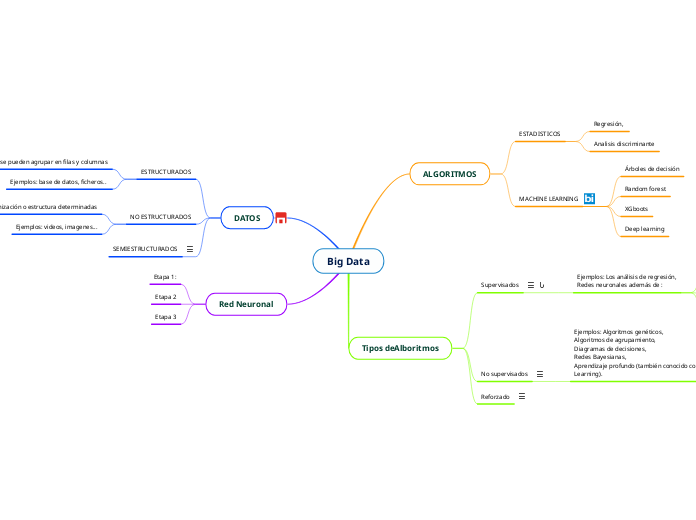
ESTADISTICOS
Regresión,
Analisis discriminante
MACHINE LEARNING
Árboles de decisión
Random forest
XGboots
Deep learning
Supervisados
Ejemplos: Los análisis de regresión,
Redes neuronales además de :
Arboles de decisión
Un árbol de decisión es un algoritmo de aprendizaje supervisado no paramétrico, que se utiliza tanto para tareas de clasificación como de regresión. Tiene una estructura de árbol jerárquica, que consta de un nodo raíz, ramas, nodos internos y nodos hoja.Comienza con un nodo raíz, sin ramas entrantes. Las ramas salientes del nodo raíz alimentan los nodos internos, o nodos de decisión. Según las características disponibles, ambos tipos de nodos realizan evaluaciones para formar subconjuntos homogéneos, indicados mediante nodos hoja o nodos terminales. Los nodos hoja representan todos los resultados posibles dentro del conjunto de datos. Fuente: https://www.ibm.com/es-es/topics/decision-trees
aN-nearest Neighbours
K-Nearest-Neighbor es un algoritmo basado en instancia de tipo supervisado de Machine Learning. Puede usarse para clasificar nuevas muestras (valores discretos) o para predecir (regresión, valores continuos).Fuente: https://www.aprendemachinelearning.com/clasificar-con-k-nearest-neighbor-ejemplo-en-python/#:~:text=K%2DNearest%2DNeighbor%20es%20un,el%20mundo%20del%20Aprendizaje%20Autom%C3%A1tico.
aMaquinas de vectores de soporte
Es un algoritmo de aprendizaje automático supervisado que se puede utilizar para problemas de clasificación o regresión. Pero generalmente se usa para clasificar. Dadas 2 o más clases de datos etiquetadas, actúa como un clasificador discriminativo, definido formalmente por un hiperplano óptimo que separa todas las clases. Los nuevos ejemplos que luego se mapean en ese mismo espacio se pueden clasificar según el lado de la brecha en que se encuentran.https://medium.com/@csarchiquerodriguez/maquina-de-soporte-vectorial-svm-92e9f1b1b1achttps://www.iartificial.net/maquinas-de-vectores-de-soporte-svm/
aNo supervisados
Tratan de usar toda la información de las variables disponbibles para intentar agruparla y/o segmentarla, relaciona las variables de entrada con las variables de salida.
Ejemplos: Algoritmos genéticos,
Algoritmos de agrupamiento,
Diagramas de decisiones,
Redes Bayesianas,
Aprendizaje profundo (también conocido como Deep Learning).
Reforzado
Busca planear qué estrategias debe adoptar una inteligencia artificial, genera estrategias automáticas.
ESTRUCTURADOS
Datos ordenados y que se pueden agrupar en filas y columnas
Ejemplos: base de datos, ficheros..
NO ESTRUCTURADOS
No presentan una organización o estructura determinadas
Ejemplos: videos, imagenes...
SEMIESTRUCTURADOS
No tienen estructura rígida como la necesaria para las bases de datos relacionales de los datos estructurados, pero tampoco carecen de la misma como los datos no estructurados
Etapa 1:
Etapa 2
Etapa 3