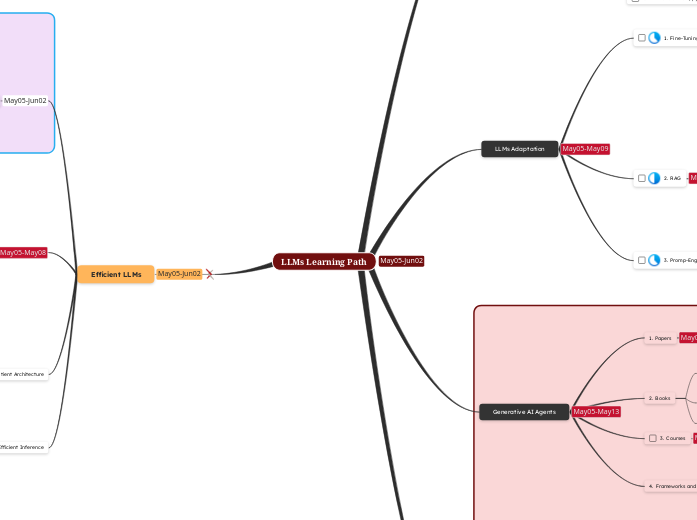
LLMs Learning Path
100
%
200%
150%
100%
75%
50%
Fit kartet
Klikk her for å
sentrere kartet ditt.
Du er ferdig med presentasjonen
Start på nytt
Legg til notat
{title}
{assignedTo}
start
slutt
Stem
Lenke
Link ble kopiert til utklippstavlen.
Legg til en kommentar ...
Vis nivåer
1
2
3
Alle