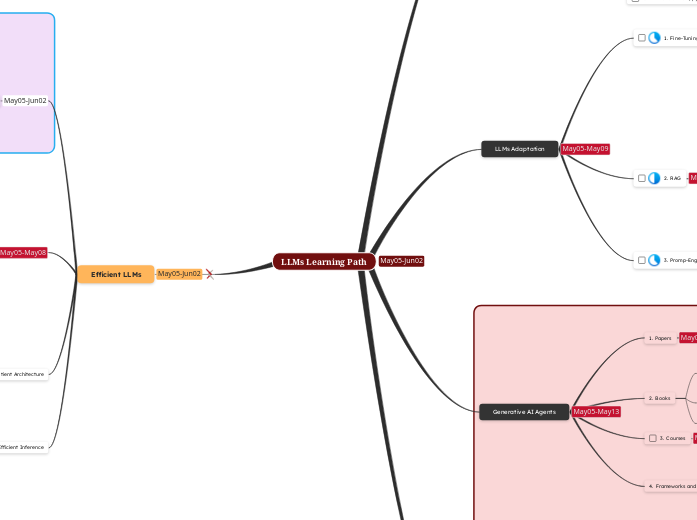
LLMs Learning Path
Click here to
center your diagram.
Click here to
center your diagram.
You've finished your presentation
Restart
Note
{title}
{assignedTo}
start
end
Vote
Link
Link was copied to your clipboard.